Running a million-board chess MMO in a single process
How One Million Chessboards works
Jun 24, 2025
One Million Chessboards is over. Thanks for playing! If you’d like to run your own version, you can find the code here.
One Million Chessboards is a 1000x1000 grid of chess boards. Moving a piece moves it for everyone, instantly. There are no turns, and pieces can move between boards.
making some moves
In the 10 days after launch, over 150,000 players made over 15,000,000 moves and hundreds of millions of queries. The game runs out of a single process that I didn’t touch over those 10 days 1.
Once activity died down I bounced the server, reset the game, and started experimenting with rule tweaks.
Making this project taught me a lot. It’s the first time I’ve used protobufs or golang, the first time I’ve measured nanoseconds, and my first time writing rollback netcode.
Let me tell you about it.
- read the code here
- play the game here
- this essay is also a video on my youtube channel, if that’s more your style
Basics
Here’s a quick overview of the site before we jump into the details.
Rules
Pieces can move between boards - I wanted one global game, not a million simultaneous ones 2.
This seemed to really disappoint actual chess players. I’m a little surprised by that - I don’t think that a million simultaneous games would lead to particularly interesting gameplay! - but maybe I’m wrong.
moving between boards
This meant that sharding the boards over many processes wasn’t free because those processes would need to communicate.
There are no turns. I didn’t think asking the whole internet to take turns would work well. And I thought real-time chess would be fun.
taking a king
This meant that speed mattered; I needed to make sure that clients could make moves fast.
I prevented pieces from capturing pieces on other boards. This was originally to prevent a queen from immediately capturing the king on the board above or below her, but ended up producing fun emergent gameplay as people (ab)used it to make indestructible structures like Rooklyn and Queens.

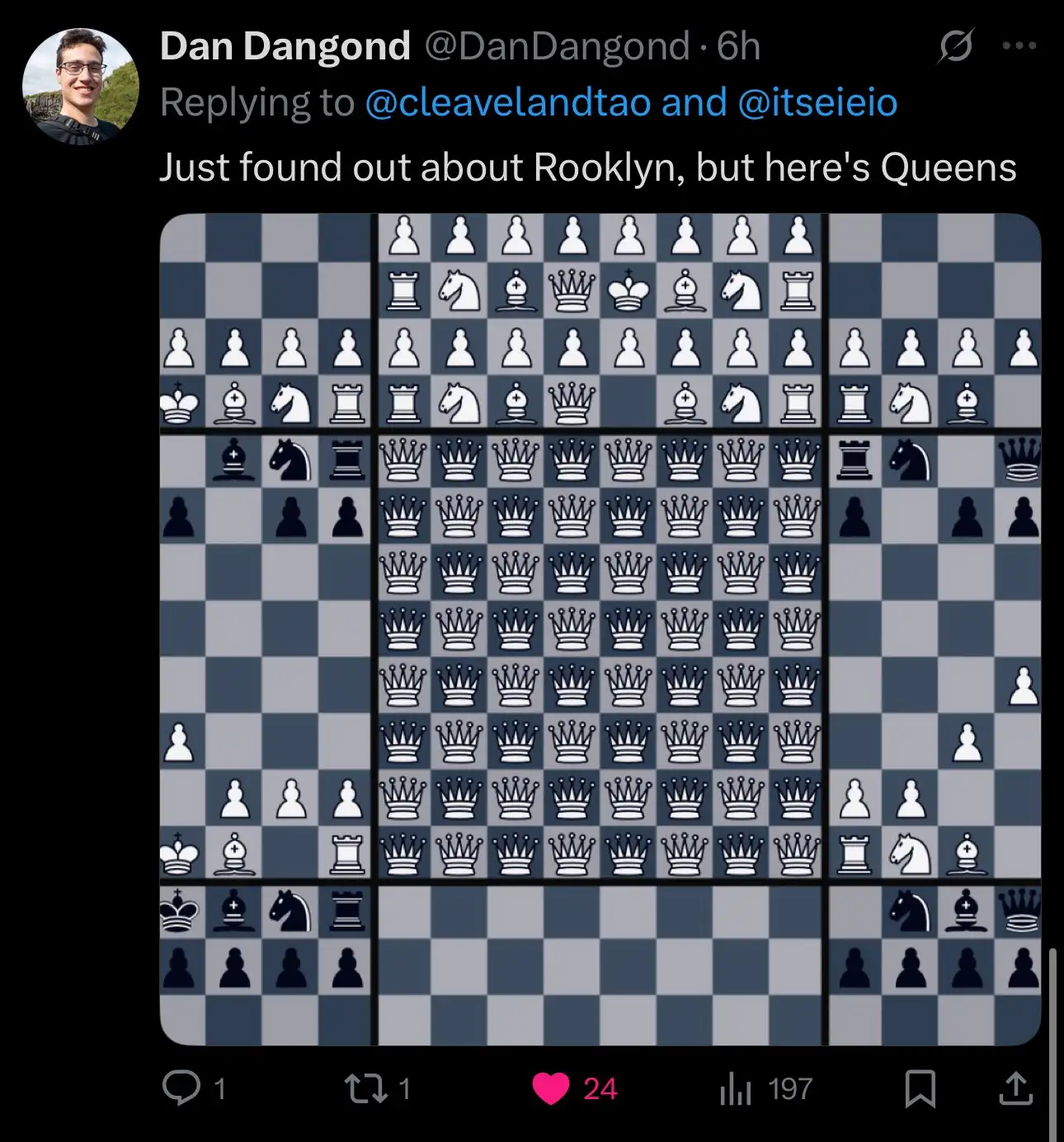

Rooklyn, Queens, and a digital monument
This rule was interesting, but it locked up the game. After activity died down I tried relaxing the restriction to only apply to unmoved pieces. I think this was a mistake - the original version was likely better.
The site has some other fun features. You can click on pieces to see how many times they’ve moved or captured a piece, there’s a minimap that lets you quickly jump to anywhere on the grid, and you can zoom out to see an overview of a larger chunk of the board at once.

15 moves and 14 captures for this queen - not bad!
System Design Goals
Last year I built a surprisingly popular site called One Million Checkboxes. I learned a lot while scaling it to handle load; those learnings directly lead to my design goals.
I wanted to minimize bandwidth since it was my one unbounded cost. It’s very stressful going to bed not knowing what you’ll owe when you wake up.
I chose to run in a single process - partially because it was easier than sharding, partially because it was a fun challenge, but primarily because I was still smarting from a Hacker News comment (correctly!) pointing out that could have run One Million Checkboxes in a single process (instead of the 8 vms and a database that I used).
This irked me because they were *right*
I aimed to be bottlenecked by syscalls or message serialization overhead. Both of those operations parallelize well, which means I could scale vertically to address them if I needed to.
And finally, I wanted to be surprisingly fast. My biggest gripe with most One Million Checkboxes clones is that they have too many loading spinners (One Million Checkboxes sent all its data to all clients which - when it wasn’t crashing - kept things snappy). I couldn’t ship all my data to clients this time so they’d have to load data occasionally - but I wanted to be faster than anyone would reasonably expect.
Basic Architecture
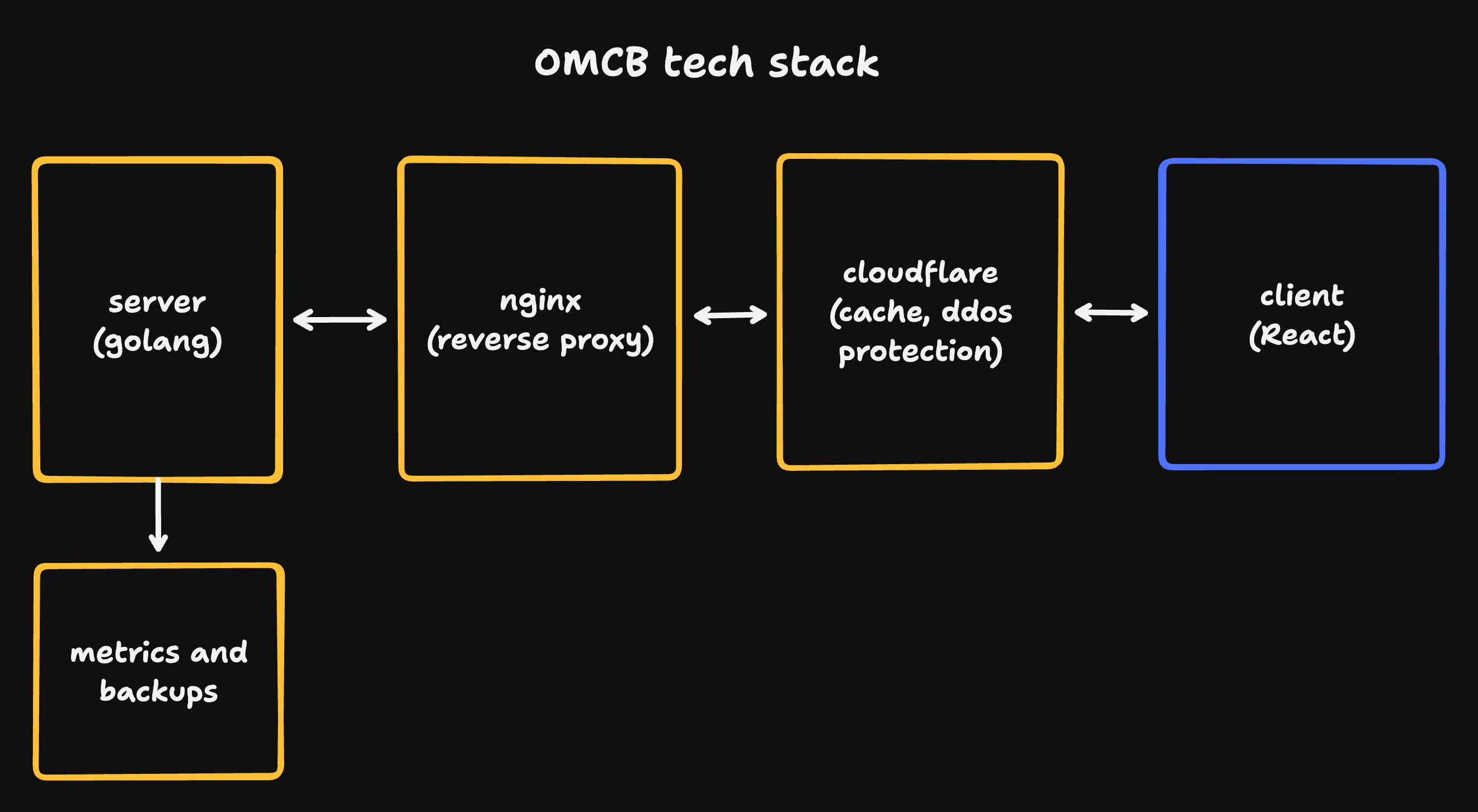
The server runs in a single golang process. It sits behind an nginx reverse proxy that sits behind cloudflare. An auxiliary VM handles metrics collection and stores backups of the game state. The frontend is written in React.
metrics are handled via vector and loki
The server has 4 core components - the board, client manager, minimap aggregator, and board to disk handler.

yes, they're all arrays, what of it
- The board is a dense 8000x8000 array of uint64s representing pieces.
- The client manager tracks the location of each client
- The minimap aggregator summarizes where pieces are
- The board to disk handler duplicates our board state and regularly serializes that state to disk
The server also has a set of goroutines (go’s lightweight threads) for every connected user. These goroutines track per-client data, accept moves, and are responsible for compressing and sending data to each client:
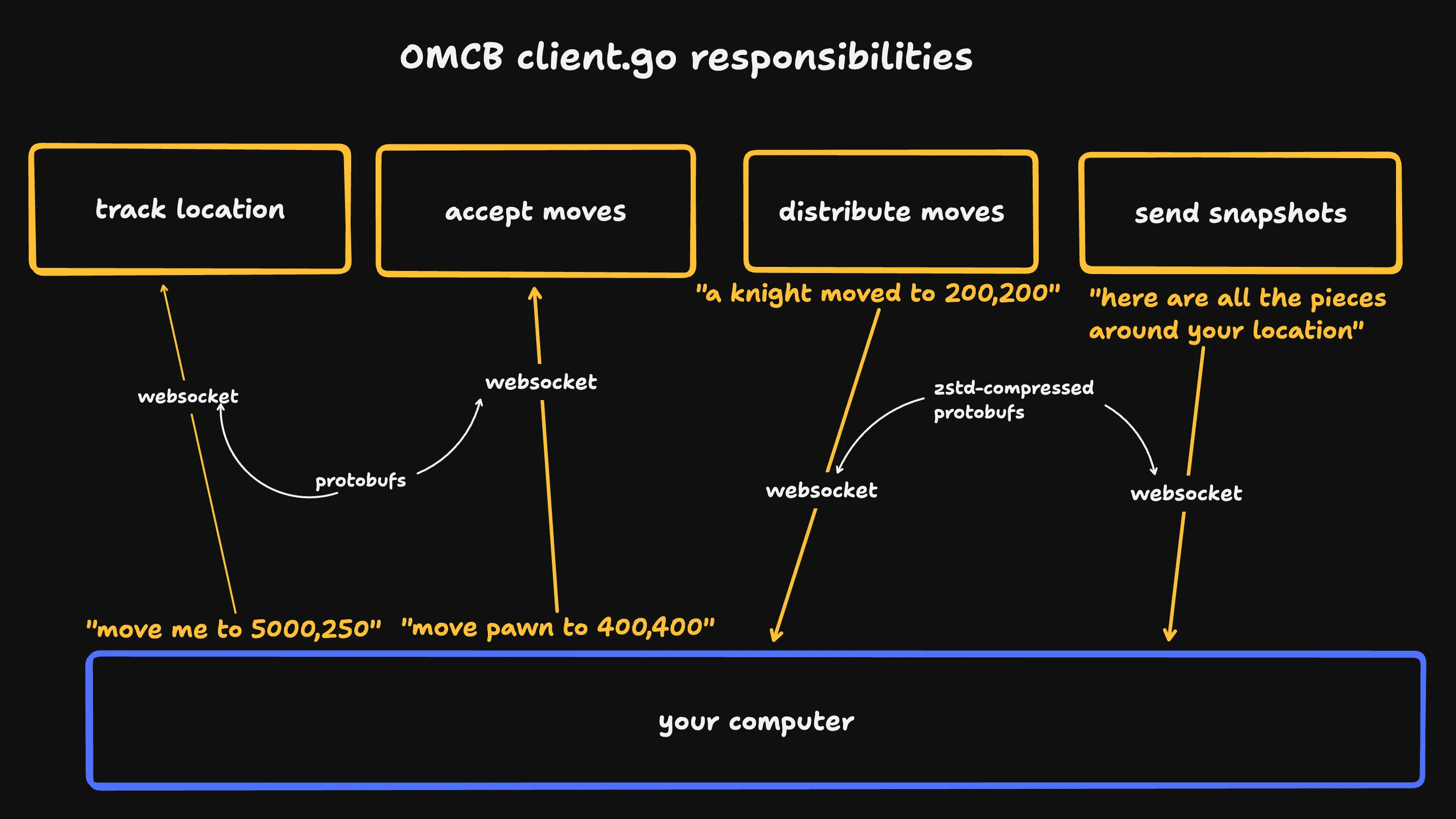
I regret calling this 'client' since it sounds like I'm referring to the website
The client has a few more responsibilities like assigning you a starting location next to another active player or tracking whether you’re playing black or white.
Distribution
One Million Chessboards starts with 32 million pieces. We can’t ship all the pieces to every client!
So we distribute state via snapshots and move batches. Snapshots and move batches are sent based on a player’s position.
- A position is the center of a player’s screen - if a player’s position is 100,100 they might see pieces between square 84,84 and square 116,116
- A snapshot is a list of all pieces in a 95x95 square around a position.
- A move batch is a list of all moves (e.g. ‘piece #2 moved to 300,300’) that have happened close to a position
When a player connects we send them a snapshot. After that we send move batches, since moves are the only way that the board state changes. As the client moves positions we send them new snapshots 3.
These updates are sent over websockets, meaning they use TCP. I think we could send some of them (at least moves) over UDP using WebRTC, which would be faster and consistent with what many networked games running outside of the browser do. I avoided this just because I knew how to use websockets and was already learning a ton of stuff for this project, but did add sequence numbers to everything so that I could swap to UDP if I needed to.
We send batches of moves to clients every 200 milliseconds (unless the batch becomes very large). Batching massively reduced load for One Million Checkboxes so I kept the same logic here.
data is fetched as the client moves so that players don't see loading screens as they scroll
The server tracks the position of the last snapshot it sent to the client. The client tells the server whenever it changes position, and the server decides when to send new snapshots.
The server sends a new snapshot if a player’s position is more than 12 horizontal or vertical tiles away from its previous position - if a client is panning around, this gets them new data before they need it, avoiding loading spinners 4.
To avoid overloading the server, the client throttles and debounces the number of “I’ve changed position” messages you can send in a second.
We also send a new snapshot every 2 minutes in case clients get into a weird state or drops a message while their tab is backgrounded.
Protocol
Updates are shipped to clients using protobufs (a binary serialization format from Google) 5 and compressed using zstd. Protobufs are small (reducing bandwidth costs) and very fast to serialize.
I also considered BSON and messagepack (too large), flatbuffers (better client-side, but harder to serialize), and Cap’N’Proto. Cap’N’Proto seems even better for my use-case than protobufs but I wasn’t confident enough in the third-party javascript tooling for it, whereas protobufjs seemed rock solid.
Snapshots and moves contain a piece id, the piece’s position, and some metadata (the piece type, move and capture counts, etc). Protobufs use a variable number of bytes to encode a number depending on its size, keeping our message size low.
These protobufs compress surprisingly well! Here are some numbers I measured before shipping:
Bandwidth usage for ~5,000 snapshots and ~575,000 moves:
76 MB - compressed protobuf
98 MB - compressed JSON
269 MB - uncompressed protobuf
2.5 GB - uncompressed unoptimized JSON
In the month of launch I shipped a bit over a terrabyte of data. I’m glad I didn’t go with uncompressed JSON!
The Right Moves
A naive algorithm for distributing state to players in a multiplayer game is often quadratic. You accept moves from N players and distribute those moves to all N players - that’s O(N^2) 6!
Forgive me - I’m playing it a little loose with N! Players may send moves at different rates. But the number of moves your game receives per second typically scales with the number of players, so this is true enough for our purposes.
Doing O(N^2) work (and having O(N^2) bandwidth usage) is scary. To do better, we want to send users all relevant moves (moves that are close to them) without sending them every move that happens.
To do this, we divide our grid into zones - 50x50 groups of tiles. And we send clients moves that happen in a 3x3 box of zones centered on their current position.
Concretely, if a client is at 255, 285 their central zone is 5,5 and their 3x3 box spans from 4,4 to 6,6.
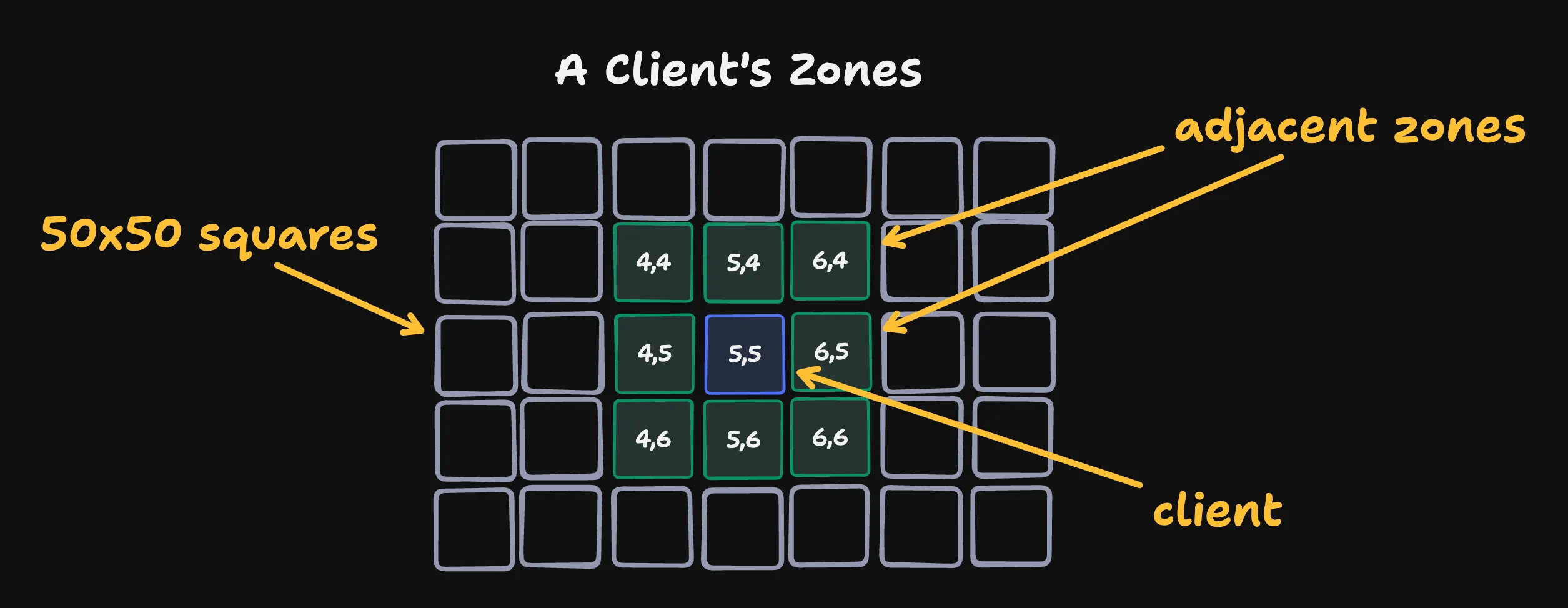
a client cares about 22,500 tiles at all times
We put all clients that currently care about a zone in a set and store those sets in a 2D array.
After we’ve validated a move, we calculate the zones that it touches. A rook moving from 395, 200 to 405, 200 is moving from zone 7,4 to zone 8,4. Then we find the clients tracking zones 7,4 or 8,4 and send them the move.
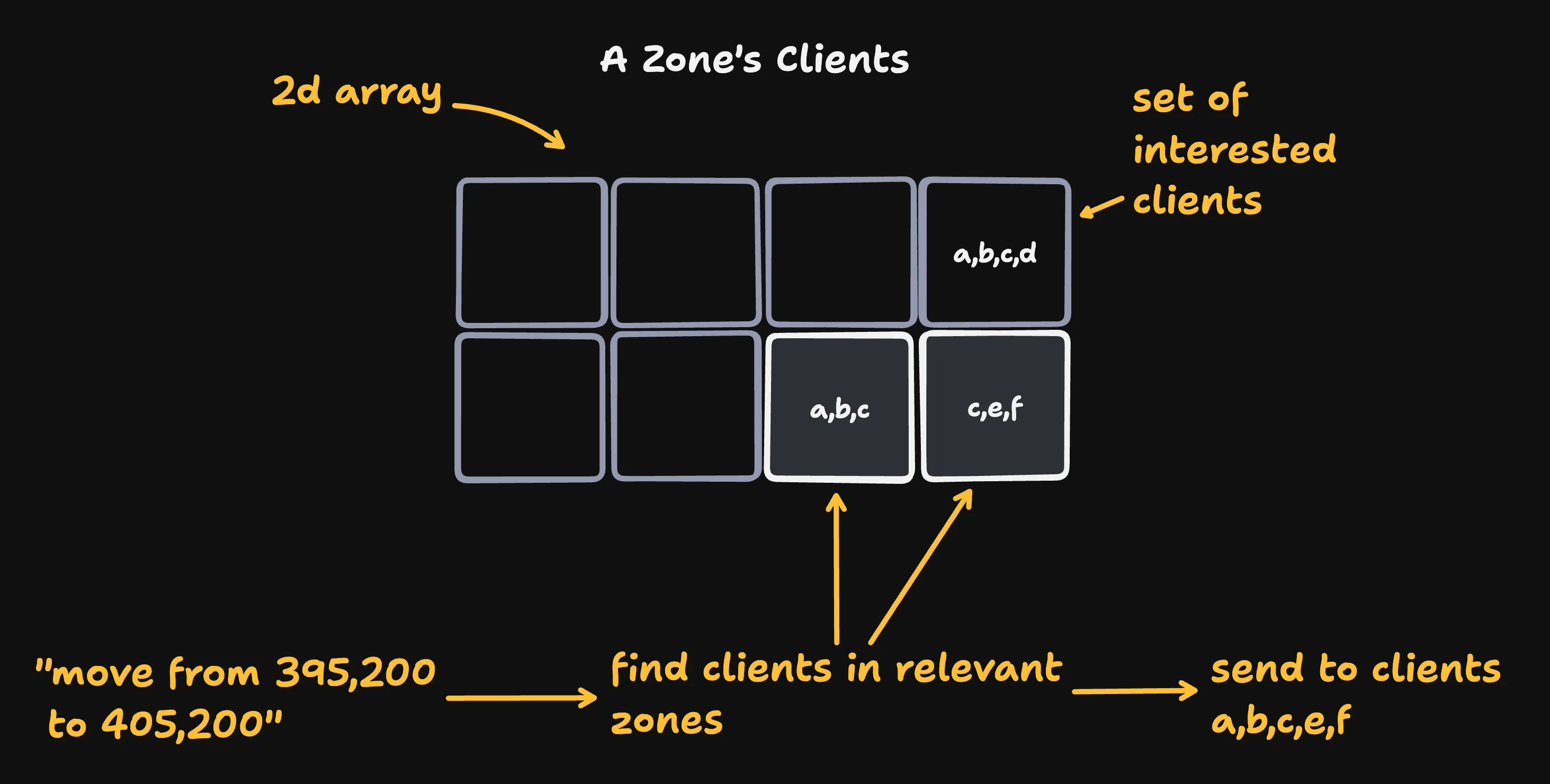
Magic Numbers
Why is a snapshot 95x95? Why do we send new snapshots if a client moves more than 12 tiles? Why is our zone size 50?
They’re all derived from the UI! I started with the fact that clients can’t see more than 35x35 tiles 7 and worked backwards. The math here isn’t super important, but you can expand the below section if you’re curious.
I chose 35x35 purely by feel.
Magic numbers details
So clients can see up to 35x35 squares when zoomed in, and 70x70 squares when zoomed out (the exact number they see is dynamically calculated by their screen size).
When a player is zoomed out, panning or using the arrow keys changes the position by up to 10 tiles. A snapshot size of 95x95 is large enough that moving by 10 tiles in any direction will never require loading data as long as a player has an up-to-date snapshot.
moving while zoomed out moves by 5 to 10 tiles
A player’s view radius as extends a maximum of 35 tiles in each direction from some central point. Our snapshots extend in 95 / 2 = 47.5 tiles in each direction from the same point. This means that we should send a new snapshot if a player’s position changes by more than 47.5 - 35 = 12.5 tiles.
We want to send a client all relevant moves while minimizing the number of moves that we send them. We can say that a move is relevant if it would have been included in the client’s last snapshot. 50 is the smallest number that evenly divides 8000 (the size of our grid) while maintaining this property.
Sending data once
Some data - like the number of connected users - is the same for everyone.
We make heavy use of Cloudflare to cache this data instead of looping over every websocket connection to send it to each user individually.
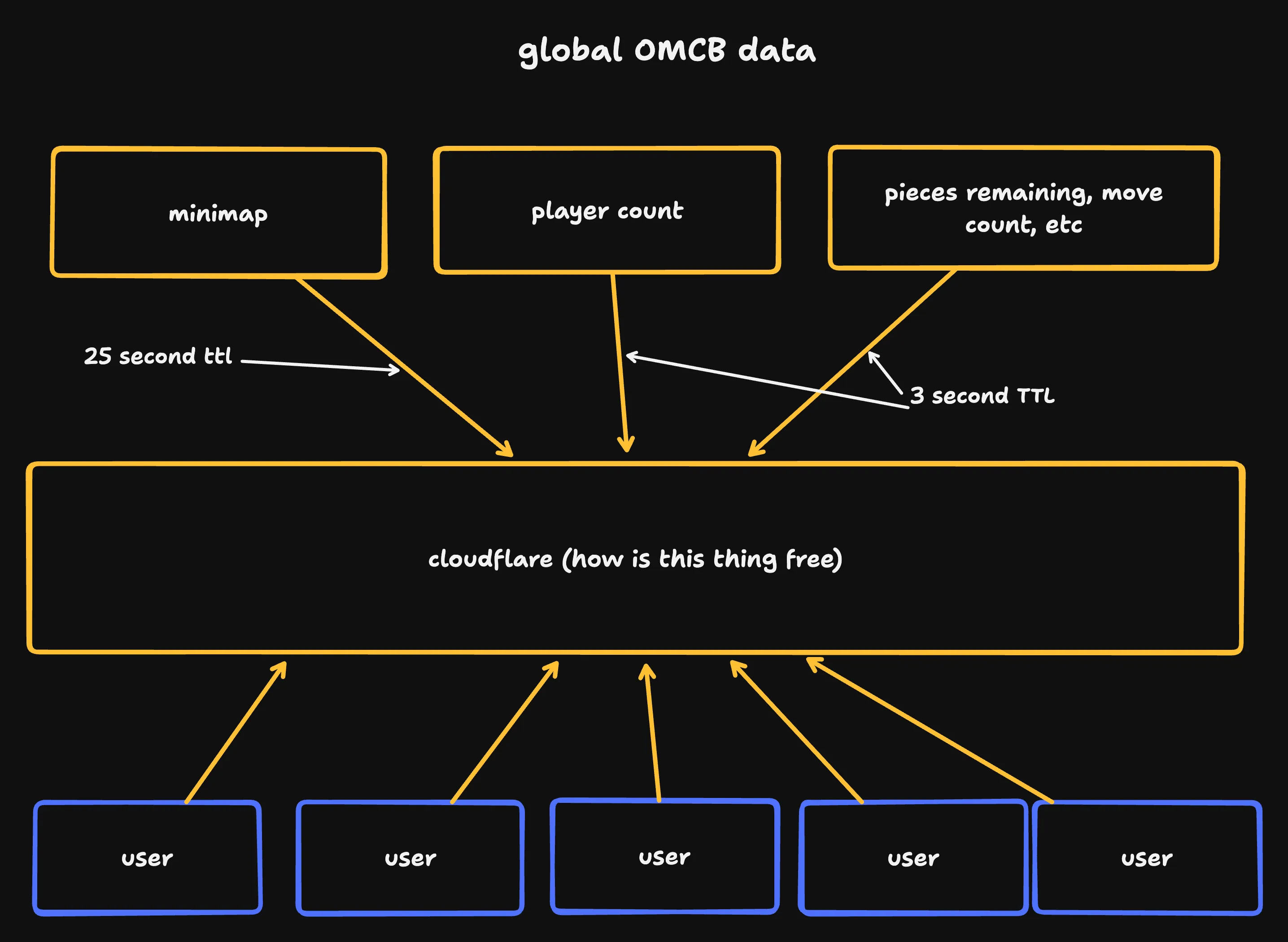
thank you cloudflare
To do this:
- Every few seconds, our server computes new values for global data
- Every few seconds, clients poll for new global data
- Our server responds to those requests with a low max-age header
- Cloudflare is configured to cache these responses based on their max-age
This (totally free!) setup has offloaded hundreds of millions of requests from my server to Cloudflare, reducing the server’s workload and bandwidth usage.
State
The board is stored as a 64 million (8000x8000) element array protected by a RWMutex (which allows many readers or one writer).
Each piece is represented as a uint64; the empty piece is 0. The board is row-major; if there’s a piece at 200,300 that piece exists at board[300][200].
type Board struct {
sync.RWMutex
pieces [8000][8000]uint64
rawRowsPool sync.Pool
seqNum uint64
totalMoves atomic.Uint64
// more atomics and logging helpers here
}
We use our 64 bits to assign each piece a unique ID (which we need client side) and to track fun metadata like the number of times that a piece has moved. This metadata also allows us to do stuff like support En Passant.
// piece bitpacking layout
const (
PieceIdShift = 0 // 2**25 > 32,000,000
// 7 piece types because a promoted pawn is a separate type
// from a queen
PieceTypeShift = 25 // 4 bits (7 piece types)
IsWhiteShift = 29 // only 1 bit ever
JustDoubleMovedShift = 30 // 1 bit (for en passant)
KingKillerShift = 31 // 1 bit
KingPawnerShift = 32 // 1 bit
QueenKillerShift = 33 // 1 bit
QueenPawnerShift = 34 // 1 bit
// "adopting" pieces is a feature I never finished
AdoptedKillerShift = 35 // 1 bit
HasCapturedPieceTypeOtherThanOwnShift = 36 // 1 bit
AdoptedShift = 39 // 1 bit
MoveCountShift = 40 // 12 bits
CaptureCountShift = 52 // 12 bits
)
Moves are fed into a go channel (roughly a threadsafe queue), where a single writer validates them (making sure they follow chess rules), applies them, and distributes them to the relevant clients.
When a client needs a snapshot they take a read lock, copy the relevant data, release the lock, and then do some post-processing before serializing and sending the snapshot.
The writer holds the write lock for about 500 nanoseconds. Readers hold the read lock for around 20 microseconds.
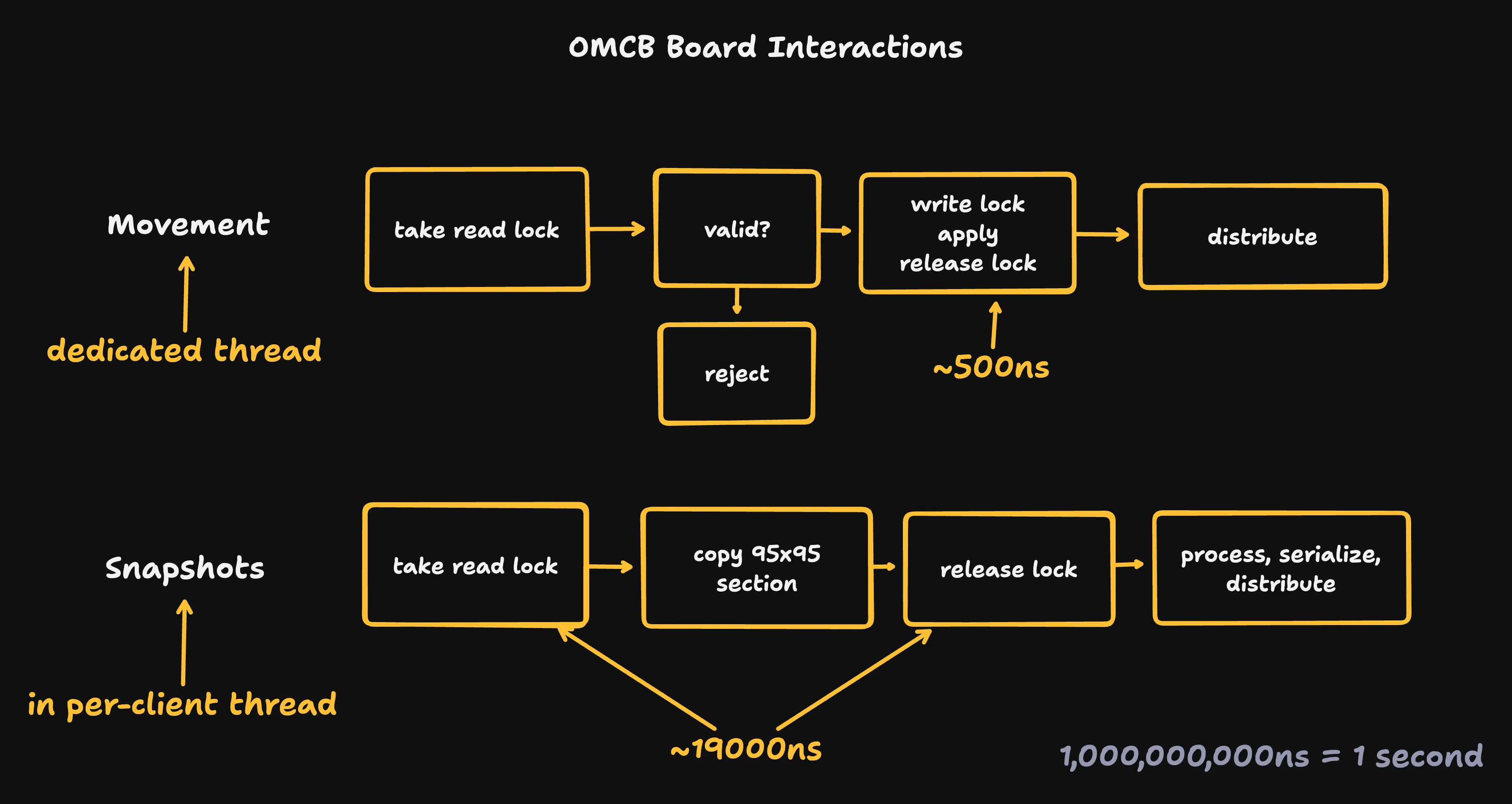
my napkin math for latency numbers was originally an order of magnitude high. oops.
Post-processing weeds out empty pieces so that we don’t serialize them. Since we want to minimize the amount of time we hold our read lock, it’s much faster to do this after releasing the lock - that way we only have to hold the lock for 95 copies instead of 9025 reads.
I picked this architecture because it is simple and easy to think about. It makes a few tradeoffs.
Dense not Sparse
We could store this data as a sparse map instead of a dense array. This would at least halve our memory usage - our board starts half empty!
But doing that would make it slower - or at least more complicated - to take snapshots. Right now a snapshot requires 95 copies of 95 sequential values. CPUs are very good at copying sequential values.
// code for taking a board snapshot
preLock := time.Now()
b.RLock()
seqnum := b.seqNum
for y := minY; y <= maxY; y++ {
copy(pieces[y-minY], b.pieces[y][minX:maxX+1])
}
b.RUnlock()
lockTook := time.Since(preLock).Nanoseconds()
64 million uint64s is 512 MB of memory. That’s not nothing, but it’s certainly within my server’s capabilities. I’m happy with the tradeoff here.
A single mutex
Using a single mutex seemed a little scary. From profiling I didn’t think it was a bottleneck, but production traffic might expose pathological cases I didn’t test.
So I considered a row-based locking approach that would likely reduce contention at the cost of complexity (and a small hit to best-case speed).
But I don’t write a lot of lock-based code. I figured the number of deadlocks I added scaled with the number of locks I added.
I decided to ship the single-mutex approach but log lock-hold times for each move and snapshot (I fed the data into loki via vector) 8.
vector was great. It was super easy to install and set up. Loki was really nice to use - I loved being able to treat it like a big greppable log file when I wanted to - but the docs for setting it up were a little frustrating. That said, I’m happy with this stack and will use it again.
// code for a "regular" (not castling or en passant) move
now := time.Now() // this should have been after b.Lock(). oops.
b.Lock()
b.pieces[move.FromY][move.FromX] = uint64(EmptyEncodedPiece)
b.pieces[move.ToY][move.ToX] = uint64(movedPiece.Encode())
b.seqNum++
seqNum := b.seqNum
b.Unlock()
took := time.Since(now).Nanoseconds()
This meant that if the site was slow I could check my metrics, see whether lock times were much higher than I expected, and swap to row-based locking if needed.
The mutex was never a problem. I’m glad I did the simple thing.
Bad napkin math
When first speccing out the backend I did some awful math.
I wanted to estimate the amount of time it would take to get a 95x95 snapshot. Latency numbers every programmer should know told me that a read from memory takes about 100ns.
Our snapshots have 9025 values. Multiplying that by 100ns told me it’d take almost a millisecond for a snapshot! That’s way too long to block the writer given that I thought we’d be read-heavy.
To speed things up I decided to fill the board with atomics - values that you can safely read and write across threads - so that I could read and write to the board concurrently.
I explained this plan to some smart friends and they told me it was bad.
thanks eliot
There are several problems with my approach. But - simplifying a lot - the big one is that reading and writing lots of atomics in a tight loop is expensive. CPUs have caches and atomic operations exist in part to make sure those caches don’t serve up stale values.
That involves telling each core “hey, make sure that you don’t have a stale value cached for this memory location.” And doing that in a tight loop for a lot of values is a lot of work. That work would eat into much (or all!) of the benefit I got from concurrency.
As I tried to figure out what to do I realized that my napkin math was way off.
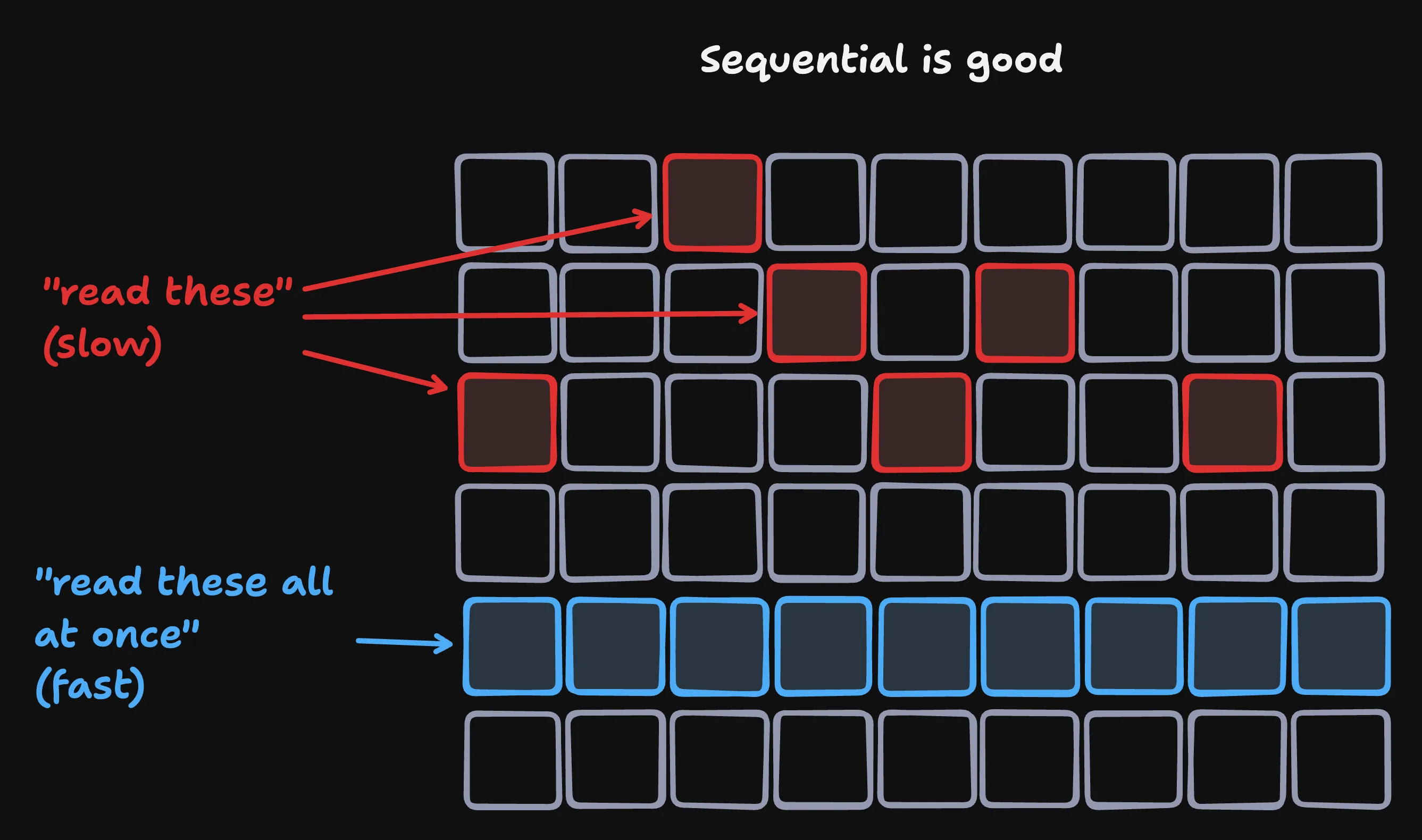
sequential good scattered bad
My snapshot isn’t 9025 arbitrary values - it’s 95 groups of 95 sequential values! And copying sequential values is really fast. I redid my math and realized that my snapshots were at least an order of magnitude faster than I had calculated. And so I moved to the single-mutex approach.
This would have been obvious to me if I spent more time thinking about performance. But it wasn’t.
That’s ok though. Learning by doing is the best way to learn. It’ll be obvious next time :)
Serialization
Since we’re not using a database, we need a way to persist our state to disk.
The naive solution here would be to take a read lock for the entire board, then read in every value and write it to disk. But that takes time - at least a second or two - and during that time players wouldn’t be able to make new moves.
To avoid that multi-second lockup we duplicate the whole board!
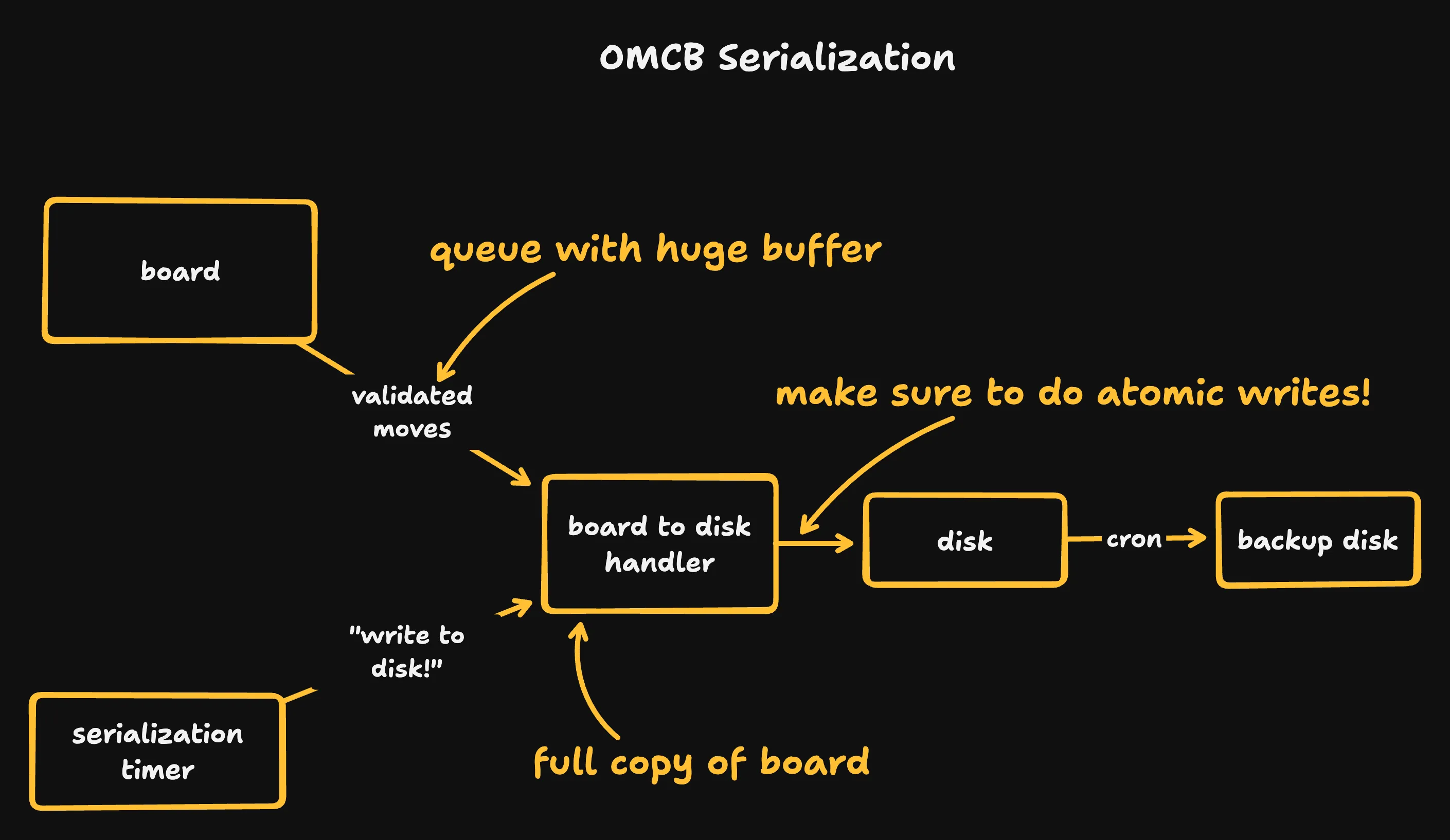
nice and simple (?)
After moves are validated, they’re re-applied to a copy of the board. We occasionally freeze that board and atomically 9 write it to disk. A cron job ferries old snapshots to another VM for archival.
“Atomically” here means “write the data to a temporary file, move that file to its final location after the write, and then call fsync.” Disks are full of Deep Magic and I suspect that I have not accounted for every possible failure mode here, but this is good enough for my purposes.
This prevents lockups unless the work queue for our copy fills up. The work queue is very large and serialization is infrequent so this isn’t a major concern.
We make sure to write out our state when the server shuts down so that we don’t lose any moves.
Rollback
Here are two clients. On one client moves happen immediately. On the other they happen after 250ms 10.
(hit the compare button to play both videos at the same time)
I think this is a reasonable estimate for round-trip latency for a WiFi-connected client that’s far from my server.
A delay of 250ms isn’t unplayable,but it’s not great. The delay also compounds; it gets more annoying as you try to move the same piece several times. Waiting 0ms feels much better.
To achieve 0ms wait times we apply moves optimistically and immediately - pieces move on the client before we hear back from the server at all. Folks often call this “rollback” or “rollback netcode.”
To do this, we separate our ground truth - actual updates from the server - from our optimistically-tracked state - moves we think we’ve made but haven’t heard back from the server about.
When our piece display renders a piece, it checks our optimistic state before referencing the ground truth.
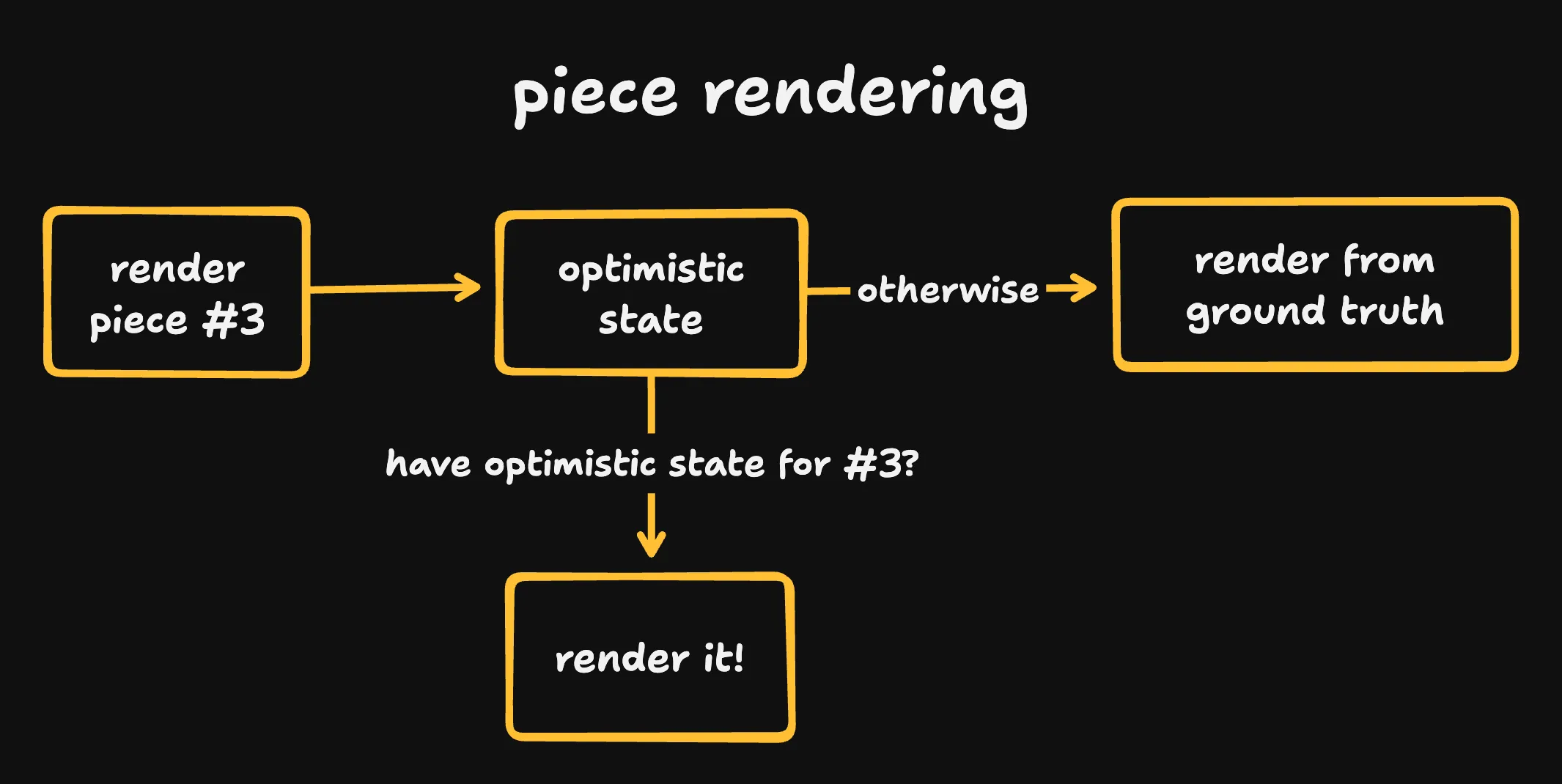
When we make a move, we give the server a “move token” that identifies it.
The server passes back that move token when accepting or rejecting a move. When it accepts a move, it also tells us the piece ID (if any) that we captured, since in some cases we may unintentionally capture a piece.

When we receive a rejection from the server we revert our move.
But wait!
Just relying on server rejections can put the board into an invalid state.
For example, here two players move different rooks to the same position (I’ll call the left client A and the right client B). A moves before B, so B learns of A’s move before it receives a server rejection message for its own move.
B rolls back its own move as soon as it learns of A’s move. If it didn’t do this - if B waited for a rejection - we’d briefly have two rooks occupying the same square.
two rooks try to occupy the same square
This can get complicated because moves can depend on each other. For example, what if you move a knight and then move a rook to where that knight was, but it turns out that the knight’s move wasn’t valid? We need to roll back both moves!
looks like we've got ourselves a dependency graph.
Edge cases
There’s more complexity lurking here than I first realized. Much of that complexity comes from precisely defining what is (and isn’t) a conflict when processing moves client side.
If two pieces of the same color occupy the same square, we always have a conflict and need to roll back.
I love watching the castle undo itself
But if two pieces of different colors occupy the same square we might not have a conflict - like here, where we move our bishop to a square and then realize that there was a black rook on that square. Instead of rolling back, we decide that we probably captured the rook.
a free piece!
Some moves - castling, advancing a pawn - aren’t allowed to capture a piece. So in that case we do need to roll back if we end up occupying the same square as a piece of the opposite color.
look, I still love watching the castle undo itself
Relatedly, we might think we captured a piece and then learn that the piece actually moved out of the way. Most of the time this is fine and we just re-add the piece to the board:
realizing that I needed to handle this was annoying
But that’s not true for pawns, since pawns can only move diagonally when they’re capturing another piece. If we failed to capture that piece, we need to roll back!
This is particularly annoying because it's just for pawns!
Actually rolling back
Once we’ve detect a conflict, we roll back all moves related to that conflict. We say two moves are related if they touch the same squares or the same pieces. We track related moves with a dependency graph.
Here’s what that might look like if we move a rook out of the way, then move a knight to the square we vacated, then move that knight again.
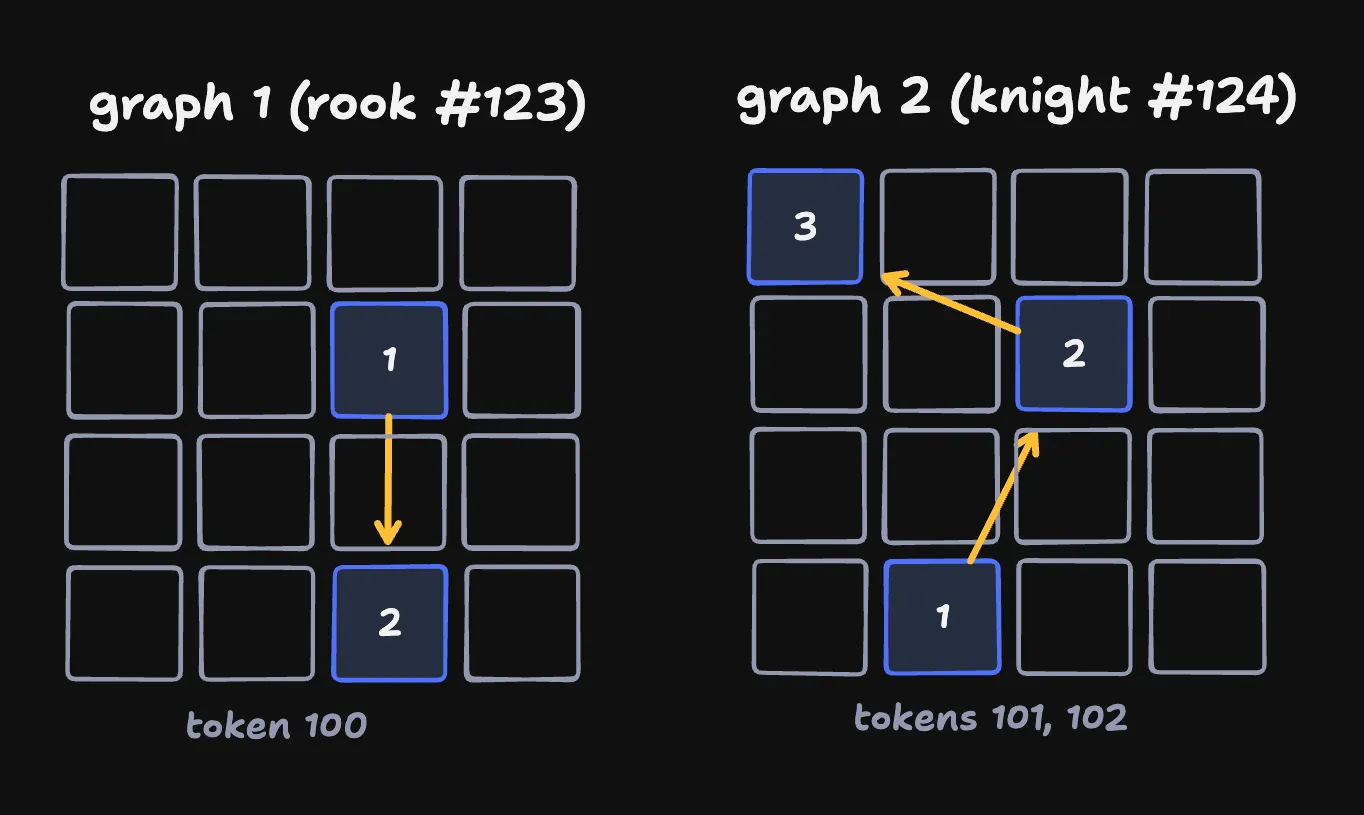
There’s a dependency here - without moving our rook out of the way we can’t move the knight to the square that it vacated! We merge dependency graphs when they touch the same squares.
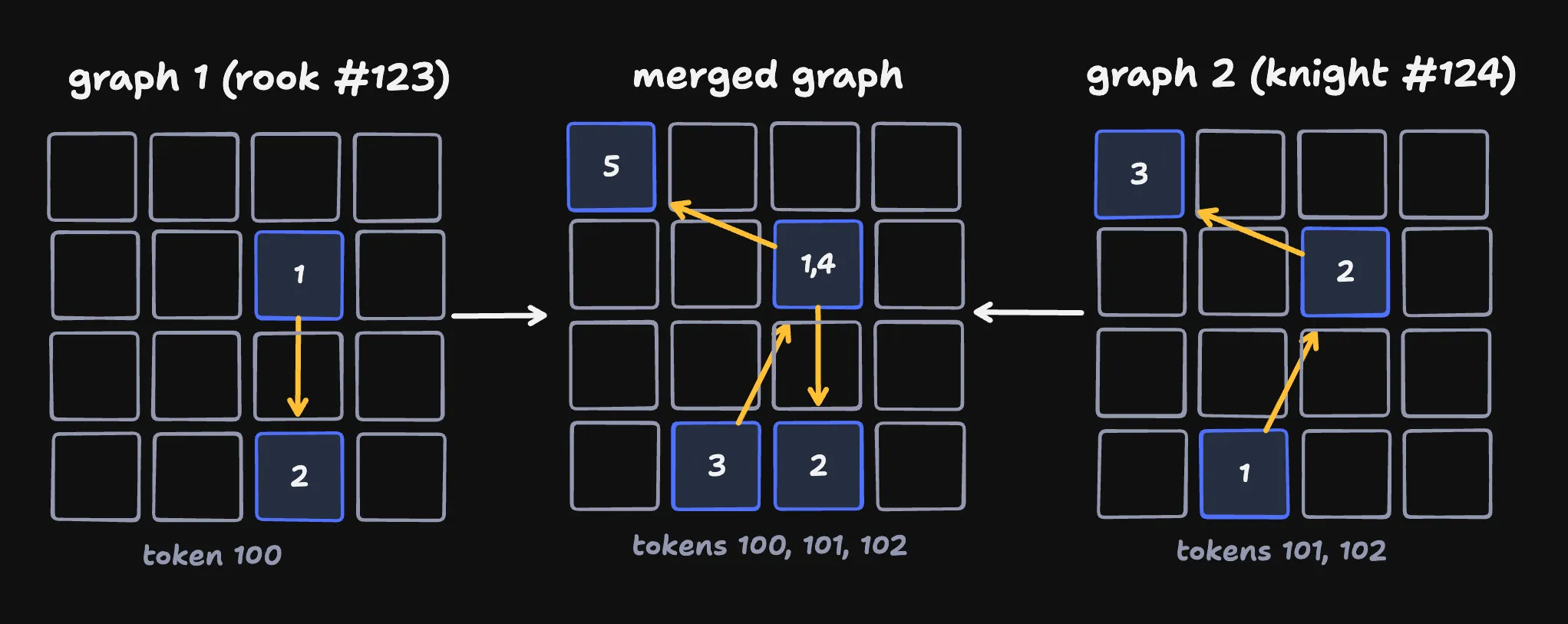
If we detect a conflict or receive a rejection, we unwind all moves in that merged graph. This is a little too aggressive - here our knight moves depend on our rook, but not vice-versa - but it simplifies the code substantially and works well enough in practice.
rolling back our graph
And as moves are confirmed, we remove them from the graph since we don’t need to unwind them anymore!
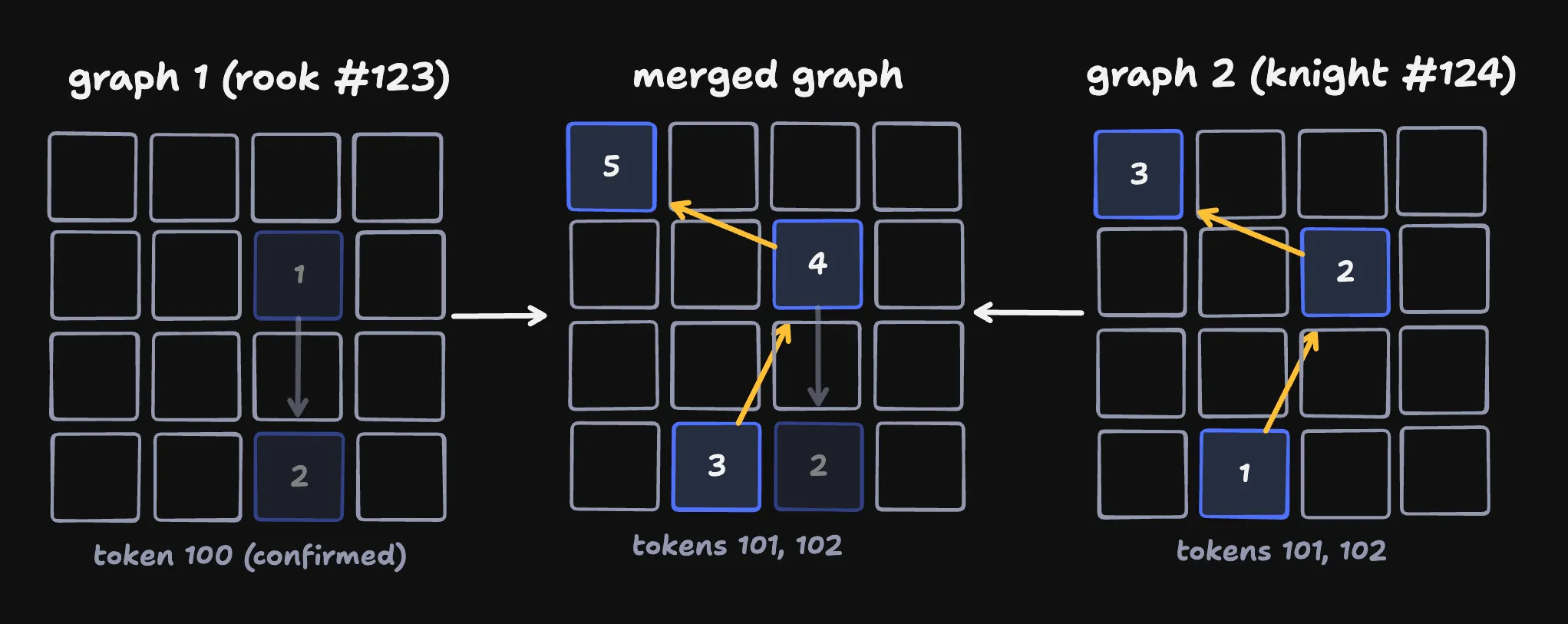
There’s a little more detail here. For eaxmple, each move (and server ack/reject) comes with a sequence number to prevent ambiguity about which move happened last. But that’s the gist.
This was really hard
Now that I understand how to think about rollback it doesn’t seem that hard. But in the moment I found it extremely challenging 11.
When I first sat down to add rollback, I made a cup of coffee at 9 PM and figured I’d program till I solved it. At around 4 AM I realized I needed to throw everything I’d done. I did the same thing (and failed again) the next night, which is around the time I realized I needed to think a little harder before starting to code.
I think that’s true of many of my favorite problems. The real challenge is taking a step back, precisely understanding your desired behavior, and forming a good mental model of the domain.
Profiling, wins, and costs
One Million Chessboards is the first game that I’ve profiled in a meaningful way before shipping. Writing in golang made this all pretty easy!
I wrote a few scripts that spun up hundreds of clients, requested lots of snapshots, and slammed a million moves through the server as fast as possible 12.
For simplicity these clients only move pawns, since pawns are easy to move in valid ways from an empty board
This was far from perfect - for example, I suspect that my profiling was more write-heavy that my actual traffic.
But it was good enough to use go’s excellent profiling tools to look at what in my code was slow and catch regressions I would have otherwise missed.
It also made it very easy to measure my bandwidth usage by just having my clients count the number of bytes that they received!
// Counting the number of received bytes across all simulated clients
// I suspect this doesn't account for headers, but it's still useful
_, message, err := ws.ReadMessage()
if err != nil {
goto restart
}
c.receivedBytes.Add(int64(len(message)))
Go was a win
My multiplayer games involve giving the whole internet concurrent read-write access (with a few rules) to a chunk of memory on a single computer.
I found golang to be perfect for this - it’s a quick language designed for concurrency that lets me reason about how memory will be laid out. I’ll be using it going forward for games like this.
Go is also a dumb language. I found myself missing the power of OCaml - the language I know best.
But that simplicify was also a boon. It pushed me to do everything with big arrays protected by mutexes. And it turns out you can go pretty far with big arrays protected by mutexes.
Costs
One Million Chessboards runs on a single Digital Ocean “CPU-optimized” box.
The night before launch I upgraded it to run on a 16-core “premium intel” box (~$450/month). I knew this was probably overkill, but I really didn’t want to deal with scaling up on launch day.
And it was massive overkill; I’m not sure I ever hit double-digit CPU usage. I’ve shrunk the box substantially (~$80/month) and I suspect I could keep going.

lol
Because my protocol optimizations keep my bandwidth usage low, this server (and my small metrics vm) are my only costs. I’ll end up spending a few hundred dollars on the project depending on how long I choose to run it in its current state.
Several folks have sent me donations (thank you!). And my costs are more than covered by tech entrepreneur / youtuber Theo, who sent in a $500 donation on launch day. Thank you very much Theo :)
Was this game good?
I’m proud of One Million Chessboards.. But I think I made some mistakes.
Folks were confused about being assigned to a single color, and the UI didn’t explain this behavior super well. Cross-board capturing was also confusing to folks, although I think some people enjoyed figuring out the rules through trial and error.
More generally, the game’s differences from standard chess turned off some chess players more than I expected - here’s a comment from the chess subreddit:
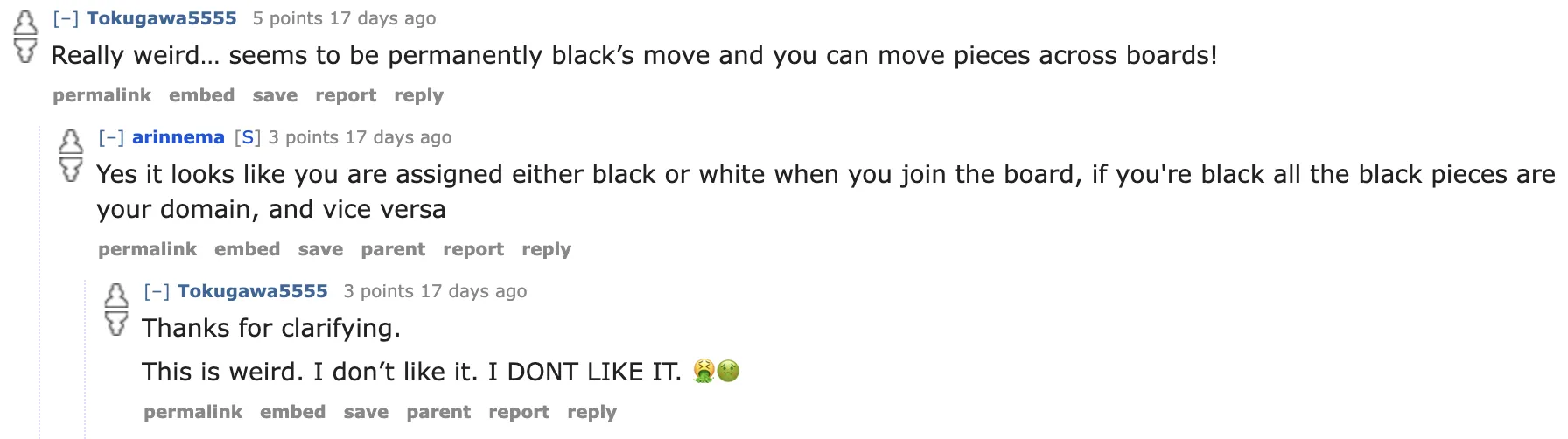
they don't like it
I’m not sure what to make of this. Maybe the game needed a tutorial or a “what is this” button?
Trying too hard to impress
Someone left this comment on Hacker News:

caveat gameator
While I don’t agree with all of this comment I think there’s some truth to the game being an exercise in scale.
I was focused on building another one million-style game. I was excited about this project because I wanted to push myself, to demonstrate that this game could be built in a single process, and to demonstrate that I was capable of building it.
I think that lead me to design decisions that existed to support the scale of the game, instead of design decisions that existed to make the game fun.
A lack of awe
I realized my biggest mistake when I tried to record footage.
Multiplayer games have a cold-start problem; they aren’t fun when you’re the only one there. To deal with this for One Million Chessboards, I use reservoir sampling (which I learned about from my friend Sam’s phenomenal blog post 13) to place new players next to someone who has made moves within the last few seconds - that way there’s some activity when you join.
Sam sent me a draft of his blog on the same day that I sent him a draft of my game - absolutely perfect timing.
This did a good job of forming clusters of players; you typically see some activity upon loading the site. But because I tuned my position assignment to form small clusters, the game failed to have the awe-inspiring “wow, there are so many people here” moment that I wanted.
With One Million Checkboxes, everyone started in the same place. That meant that even early on the top few rows of checkboxes looked crazy, which I think drew people in. It’s cool to interact with strangers on the internet!
One Million Checkboxes, 30 minutes in
I wasn’t able to record similar footage for One Million Chessboards; even with a thousand players online it didn’t feel like there were lots of people on the site.
I don’t know how to fix this. Because boards empty out over time, I couldn’t put everyone in the same starting position 14.
Well I could, but that starting spot would quickly become empty! Varying the default starting location over time might work, but I suspect there’s some kind of issue with that choice in practice.
But I’ve learned a really valuable lesson!
My favorite way to learn is to identify a totally new thing that I can think about as a first-class problem.
Prior to One Million Chessboards I knew I had to think about the multiplayer cold-start problem. I tried to address that by building up an audience so that my games would have some players at launch 15.
Way back when I made stranger video I solved this issue by spending 8 hours straight on the site on launch day so that people had someone to play against!
But now I know that conveying a game’s scale immediately when you load in is critical, and that telling folks “there are 1,000 players online” isn’t enough. Knowing that will make my next massively multiplayer game better.
Wrapping up
Thank you to my friends Won Chun, Freeman Jiang, and Eliot for their help building this; my go would have been worse and my site substantially slower without your help.
And thank you to the Recurse Center - I built this site and wrote this blog at Recurse. Recurse is the best place I know of to build sites like this (or to learn how to build sites like this!) - if that sounds fun to you you should apply.
Fear of trying
I have made many of my most popular projects in 2-4 days. This project took 15 times longer. That terrified me.
Last year, after the heights of One Million Checkboxes, I released a game called PacCam. I worked on it for an embarrasingly long time and had high hopes; I thought after One Million Checkboxes folks would pay attention to my next game.
Instead it was a flop; it got less traction than many of the things I made before I found an audience with One Million Checkboxes. And that crushed me - it made me want to stop making games.
Now I can look back on PacCam and see all sorts of problems. But in the moment the experience pushed me towards very short projects - things I could make in a week or less. Plenty of those projects went well (great!) and I wasn’t super attached to the ones that went poorly since I made them quickly.
But I knew I couldn’t make One Million Chessboards the way that I wanted to in a week. I wanted it to be great - not just a prototype - on release. I wanted to learn from my mistakes, to make something fast, to surprise and delight and wow people. And to show that I could do it.
So I chose to push through that fear, pour myself into the project, and hope for the best. When I finished I wasn’t sure what I needed to call the project a success.
One feature I added to One Million Chessboards was piece achievements. Some were simple, like an achievement for capturing a king. But some were harder to find.
A few days in, Ali found the trickiest achievement - a piece is granted “self-hating” if it captures a lot of pieces of its own kind and no other pieces.
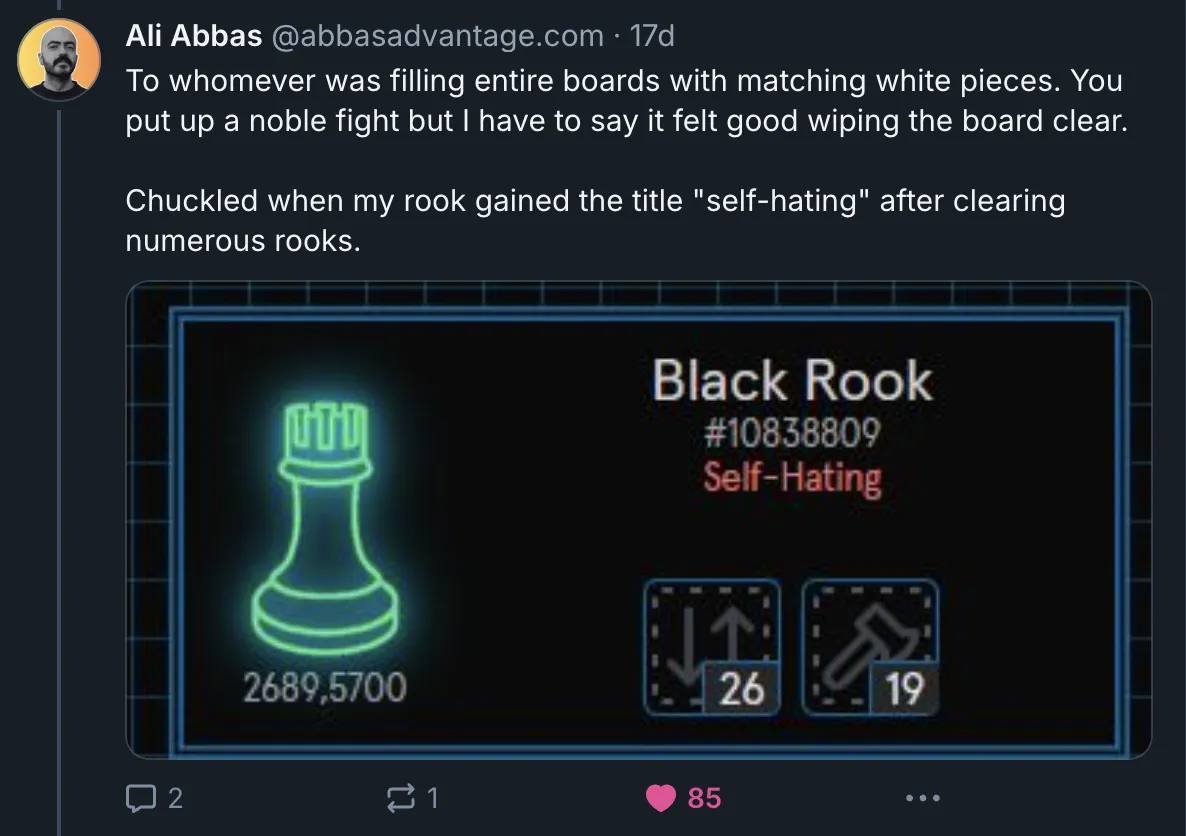
those poor Rooks
This wasn’t my biggest hidden feature, and it was far from the hardest one to add (that’d be rollback!). But it wasn’t something that I needed to add - I’d guess under 0.1% of players ever saw it.
Ali noticed that - and told me that it was in that moment that they thought ‘I think this game was made with love!’
❤️
I don’t think I can ask for anything more.
More high-effort (and low-effort) games soon.